



1 摘要
本篇文章是 Builtin 专题的第七篇。上篇文章讲解了 Builtin::kInterpreterEntryTrampoline 源码,本篇文章将介绍 Builin 的编译过程,在此过程中可以看到 Bytecode hanlder 生成 code 的技术细节,同时也可借助此过程了解 Compiler Pipeline 技术和重要数据结构。
2 Bytecode handler的重要数据结构
GenerateBytecodeHandler()负责生成Bytecode hander,源码如下:
- Handle<Code> GenerateBytecodeHandler(Isolate isolate, const char debug_name,
- Bytecode bytecode,
- OperandScale operand_scale,
- int builtin_index,
- const AssemblerOptions& options) {
- Zone zone(isolate->allocator(), ZONE_NAME);
- compiler::CodeAssemblerState state(
- isolate, &zone, InterpreterDispatchDescriptor{}, Code::BYTECODE_HANDLER,
- debug_name,
- FLAG_untrusted_code_mitigations
- ? PoisoningMitigationLevel::kPoisonCriticalOnly
- : PoisoningMitigationLevel::kDontPoison,
- builtin_index);
- switch (bytecode) {
-
define CALL_GENERATOR(Name, ...) \
- case Bytecode::k##Name: \
- Name##Assembler::Generate(&state, operand_scale); \
- break;
- BYTECODE_LIST(CALL_GENERATOR);
-
undef CALL_GENERATOR
- }
- Handle<Code> code = compiler::CodeAssembler::GenerateCode(&state, options);
-
ifdef ENABLE_DISASSEMBLER
- if (FLAG_trace_ignition_codegen) {
- StdoutStream os;
- code->Disassemble(Bytecodes::ToString(bytecode), os);
- os << std::flush;
- }
-
endif // ENABLE_DISASSEMBLER
- return code;
- }
上述代码第 7-13 行初始化 state,state 中包括 BytecodeOffset、 DispatchTable 和 Descriptor,Bytecode 编译时会使用state。 第 14-21 行代码生成 Bytecode handler 源码。第 17 行 state 作为参数传入 GenerateCode() 中,用于记录 Bytecode hadler 的生成结果。下面以 LdaSmi 为例讲解 Bytecode handler 的重要数据结构:
IGNITION_HANDLER(LdaSmi, InterpreterAssembler) {
TNode<Smi> smi_int = BytecodeOperandImmSmi(0);
SetAccumulator(smi_int);
Dispatch();
}
上述代码将累加寄存器的值设置为 smi。展开宏 IGNITION_HANDLER 后可以看到 LdaSmiAssembler 是子类,InterpreterAssembler 是父类,说明如下:
(1) LdaSmiAssembler 中包括生成 LdaSmi 的入口方法 Genrate(),源码如下:
1.void Name##Assembler::Generate(compiler::CodeAssemblerState* state,
- OperandScale scale) {
- Name##Assembler assembler(state, Bytecode::k##Name, scale);
- state->SetInitialDebugInformation(#Name, FILE, LINE);
- assembler.GenerateImpl();
6.}
上述第3行代码创建 LdaSmiAssembler 实例。第4行代码把 debug 信息写入state。
(2) InterpreterAssembler 提供解释器相关的功能,源码如下:
- class V8_EXPORT_PRIVATE InterpreterAssembler : public CodeStubAssembler {
- public:
- //.............省略.........................
- private:
- TNode<BytecodeArray> BytecodeArrayTaggedPointer();
- TNode<ExternalReference> DispatchTablePointer();
- TNode<Object> GetAccumulatorUnchecked();
- TNode<RawPtrT> GetInterpretedFramePointer();
- compiler::TNode<IntPtrT> RegisterLocation(Register reg);
- compiler::TNode<IntPtrT> RegisterLocation(compiler::TNode<IntPtrT> reg_index);
- compiler::TNode<IntPtrT> NextRegister(compiler::TNode<IntPtrT> reg_index);
- compiler::TNode<Object> LoadRegister(compiler::TNode<IntPtrT> reg_index);
- void StoreRegister(compiler::TNode<Object> value,
- compiler::TNode<IntPtrT> reg_index);
- void CallPrologue();
- void CallEpilogue();
- void TraceBytecodeDispatch(TNode<WordT> target_bytecode);
- void TraceBytecode(Runtime::FunctionId function_id);
- void Jump(compiler::TNode<IntPtrT> jump_offset, bool backward);
- void JumpConditional(compiler::TNode<BoolT> condition,
- compiler::TNode<IntPtrT> jump_offset);
- void SaveBytecodeOffset();
- TNode<IntPtrT> ReloadBytecodeOffset();
- TNode<IntPtrT> Advance();
- TNode<IntPtrT> Advance(int delta);
- TNode<IntPtrT> Advance(TNode<IntPtrT> delta, bool backward = false);
- compiler::TNode<WordT> LoadBytecode(compiler::TNode<IntPtrT> bytecode_offset);
- void DispatchToBytecodeHandlerEntry(compiler::TNode<RawPtrT> handler_entry,
- compiler::TNode<IntPtrT> bytecode_offset);
- int CurrentBytecodeSize() const;
- OperandScale operand_scale() const { return operandscale; }
- Bytecode bytecode_;
- OperandScale operandscale;
- CodeStubAssembler::TVariable<RawPtrT> interpreted_framepointer;
- CodeStubAssembler::TVariable<BytecodeArray> bytecodearray;
- CodeStubAssembler::TVariable<IntPtrT> bytecodeoffset;
- CodeStubAssembler::TVariable<ExternalReference> dispatchtable;
- CodeStubAssembler::TVariable<Object> accumulator_;
- AccumulatorUse accumulatoruse;
- bool madecall;
- bool reloaded_frameptr;
- bool bytecode_arrayvalid;
- DISALLOW_COPY_AND_ASSIGN(InterpreterAssembler);
- };
上述第 5 行代码获取 BytecodeArray 的地址;第 6 行代码获取 DispatchTable 的地址;第 7 行代码获取累加寄存器的值;第8-13行代码用于操作寄存器;第 15-16 行代码用于调用函数前后的堆栈处理;第 17-18 行代码用于跟踪 Bytecode,其中第18行会调用Runtime::RuntimeInterpreterTraceBytecodeEntry以输出寄存器信息;第 19-20 行代码是两条跳转指令,在该指令的内部调用 Advance(第24-26行)来完成跳转操作;第 24-26 行代码用于获取下一条 Bytecode;第 32-42 行代码定义的成员变量在 Bytecode handler 中会被频繁使用,例如在 SetAccumulator(zero_value) 中先设置 accumulator_use 为写状态,再把值写入 accumulator_。
(3) CodeStubAssembler 是 InterpreterAssembler 的父类,提供 JavaScript 的特有方法,源码如下:
- class V8_EXPORT_PRIVATE CodeStubAssembler: public compiler::CodeAssembler,
- public TorqueGeneratedExportedMacrosAssembler {
- public:
- TNode<Int32T> StringCharCodeAt(SloppyTNode<String> string,
- SloppyTNode<IntPtrT> index);
- TNode<String> StringFromSingleCharCode(TNode<Int32T> code);
- TNode<String> SubString(TNode<String> string, TNode<IntPtrT> from,
- TNode<IntPtrT> to);
- TNode<String> StringAdd(Node* context, TNode<String> first,
- TNode<String> second);
- TNode<Number> ToNumber(
- SloppyTNode<Context> context, SloppyTNode<Object> input,
- BigIntHandling bigint_handling = BigIntHandling::kThrow);
- TNode<Number> ToNumber_Inline(SloppyTNode<Context> context,
- SloppyTNode<Object> input);
- TNode<BigInt> ToBigInt(SloppyTNode<Context> context,
- SloppyTNode<Object> input);
- TNode<Number> ToUint32(SloppyTNode<Context> context,
- SloppyTNode<Object> input);
- // ES6 7.1.17 ToIndex, but jumps to range_error if the result is not a Smi.
- TNode<Smi> ToSmiIndex(TNode<Context> context, TNode<Object> input,
- Label* range_error);
- TNode<Smi> ToSmiLength(TNode<Context> context, TNode<Object> input,
- Label* range_error);
- TNode<Number> ToLength_Inline(SloppyTNode<Context> context,
- SloppyTNode<Object> input);
- TNode<Object> GetProperty(SloppyTNode<Context> context,
- SloppyTNode<Object> receiver, Handle<Name> name) {}
- TNode<Object> GetProperty(SloppyTNode<Context> context,
- SloppyTNode<Object> receiver,
- SloppyTNode<Object> name) {}
- TNode<Object> SetPropertyStrict(TNode<Context> context,
- TNode<Object> receiver, TNode<Object> key,
- TNode<Object> value) {}
- template <class... TArgs>
- TNode<Object> CallBuiltin(Builtins::Name id, SloppyTNode<Object> context,
- TArgs... args) {}
- template <class... TArgs>
- void TailCallBuiltin(Builtins::Name id, SloppyTNode<Object> context,
- TArgs... args) { }
- void LoadPropertyFromFastObject(...省略参数...);
- void LoadPropertyFromFastObject(...省略参数...);
- void LoadPropertyFromNameDictionary(...省略参数...);
- void LoadPropertyFromGlobalDictionary(...省略参数...);
- void UpdateFeedback(Node feedback, Node feedback_vector, Node* slot_id);
- void ReportFeedbackUpdate(TNode<FeedbackVector> feedback_vector,
- SloppyTNode<UintPtrT> slot_id, const char* reason);
- void CombineFeedback(Variable* existing_feedback, int feedback);
- void CombineFeedback(Variable existing_feedback, Node feedback);
- void OverwriteFeedback(Variable* existing_feedback, int new_feedback);
- void BranchIfNumberRelationalComparison(Operation op,
- SloppyTNode<Number> left,
- SloppyTNode<Number> right,
- Label if_true, Label if_false);
- void BranchIfNumberEqual(TNode<Number> left, TNode<Number> right,
- Label if_true, Label if_false) {
- }
- };
CodeStubAssembler 利用汇编语言实现了 JavaScript 的特有方法。基类 CodeAssembler 对汇编语言进行封装, CodeStubAssembler 使用 CodeAssembler 提供的汇编功能实现了字符串转换、属性获取和分支跳转等 JavaScript 功能,这正是 CodeStubAssembler 的意义所在。
上述代码第 4-9 行实现了字符串的相关操作;第 11-18 行代码实现了类型转换;第 21-26 行实现了 ES 规范中的功能;第 27-38 行实现了获取和设置属性;第 39-43 行实现了 Builtin 和 Runtime API 的调用方法;第 45-50 行代码用于管理 Feedback;第 51-55 行实现了 IF 功能。
(4) CodeAssembler 封装了汇编功能,实现了 Branch、Goto 等功能,源码如下:
- class V8_EXPORT_PRIVATE CodeAssembler {
- void Branch(TNode<BoolT> condition,
- CodeAssemblerParameterizedLabel<T...>* if_true,
- CodeAssemblerParameterizedLabel<T...>* if_false, Args... args) {
- if_true->AddInputs(args...);
- if_false->AddInputs(args...);
- Branch(condition, if_true->plain_label(), if_false->plain_label());
- }
- template <class... T, class... Args>
- void Goto(CodeAssemblerParameterizedLabel<T...>* label, Args... args) {
- label->AddInputs(args...);
- Goto(label->plain_label());
- }
- void Branch(TNode<BoolT> condition, const std::function<void()>& true_body,
- const std::function<void()>& false_body);
- void Branch(TNode<BoolT> condition, Label* true_label,
- const std::function<void()>& false_body);
- void Branch(TNode<BoolT> condition, const std::function<void()>& true_body,
- Label* false_label);
- void Switch(Node index, Label default_label, const int32_t* case_values,
- Label** case_labels, size_t case_count);
- }
3 Compiler Pipeline
GenerateBytecodeHandler() 的第 22 行代码完成了对 Bytecode LdaSmi 的编译,源码如下:
- Handle<Code> CodeAssembler::GenerateCode(CodeAssemblerState* state,
- const AssemblerOptions& options) {
- RawMachineAssembler* rasm = state->rawassembler.get();
- Handle<Code> code;
- Graph* graph = rasm->ExportForOptimization();
- code = Pipeline::GenerateCodeForCodeStub(...省略参数...)
- .ToHandleChecked();
- state->codegenerated = true;
- return code;
- }
- //.............分隔线...................
- MaybeHandle<Code> Pipeline::GenerateCodeForCodeStub(...省略参数...) {
- OptimizedCompilationInfo info(CStrVector(debug_name), graph->zone(), kind);
- info.set_builtin_index(builtin_index);
- if (poisoning_level != PoisoningMitigationLevel::kDontPoison) {
- info.SetPoisoningMitigationLevel(poisoning_level);
- }
- // Construct a pipeline for scheduling and code generation.
- ZoneStats zone_stats(isolate->allocator());
- NodeOriginTable node_origins(graph);
- JumpOptimizationInfo jump_opt;
- bool should_optimize_jumps =
- isolate->serializer_enabled() && FLAG_turbo_rewrite_far_jumps;
- PipelineData data(&zone_stats, &info, isolate, isolate->allocator(), graph,
- nullptr, source_positions, &node_origins,
- should_optimize_jumps ? &jump_opt : nullptr, options);
- data.set_verify_graph(FLAG_verify_csa);
- std::unique_ptr<PipelineStatistics> pipeline_statistics;
- if (FLAG_turbo_stats || FLAG_turbo_stats_nvp) {
- }
- PipelineImpl pipeline(&data);
- if (info.trace_turbo_json_enabled() || info.trace_turbo_graph_enabled()) {//..省略...
- }
- pipeline.Run<CsaEarlyOptimizationPhase>();
- pipeline.RunPrintAndVerify(CsaEarlyOptimizationPhase::phase_name(), true);
- // .............省略..............
- PipelineData second_data(...省略参数...);
- second_data.set_verify_graph(FLAG_verify_csa);
- PipelineImpl second_pipeline(&second_data);
- second_pipeline.SelectInstructionsAndAssemble(call_descriptor);
- Handle<Code> code;
- if (jump_opt.is_optimizable()) {
- jump_opt.set_optimizing();
- code = pipeline.GenerateCode(call_descriptor).ToHandleChecked();
- } else {
- code = second_pipeline.FinalizeCode().ToHandleChecked();
- }
- return code;
- }
上述第 6 行代码进入Pipeline开始编译工作;第 13-29 用于设置 Pipeline 信息;第 32 行的使能标记在 flag-definitions.h 中定义,它们使用 Json 输出当前的编译信息;第 34-40 行代码实现了生成初始汇编码、对初始汇编码进行优化、使用优化后的数据再次生成最终代码等功能,注意 第 36 行代码省略了优化初始汇编码。图1给出了 LdaSmi 的编译结果。
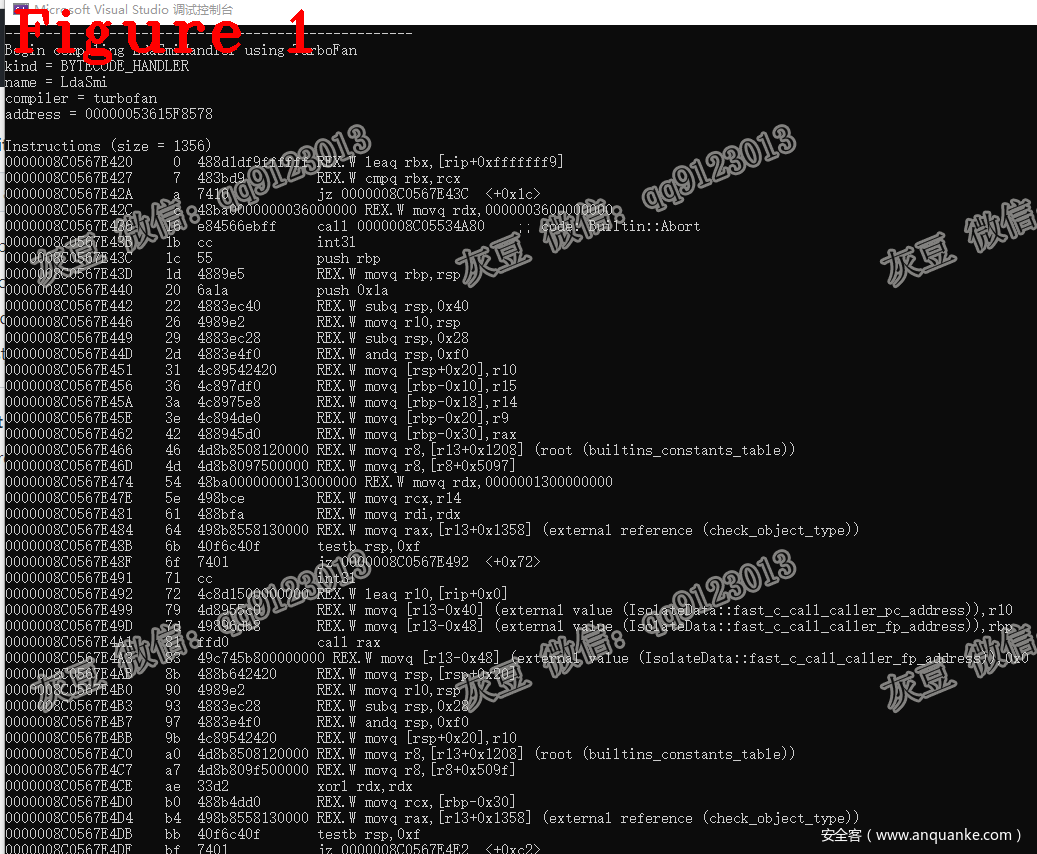
技术总结
(1) 只有 v8_use_snapshot = false 时才能在 V8 中调试 Bytecode Handler 的编译过程;
(2) CodeAssembler 封装了汇编,CodeStubAssembler 封装了JavaScript特有的功能,InterpreterAssembler 封装了解释器需要的功能,在这三层封装之上是Bytecode Handler;
(3) V8 初始化时编译包括 Byteocde handler 在内的所有 Builtin。
好了,今天到这里,下次见。
个人能力有限,有不足与纰漏,欢迎批评指正
微信:qq9123013 备注:v8交流 邮箱:v8blink@outlook.com
文章原文链接:https://www.anquanke.com/post/id/262468

